The post Django vs. Rails in 2019 (hint: there is a clear winner) appeared first on Hacker Notes.
]]>tl;dr – in 2019, unless you have some critical dependency on a Python library and you cannot work around it with a service-wise integration, just choose Rails.
Without further ado, here is a point-by-point assessment of Django in relation to Ruby on Rails in 2019:
1) No intelligent reloading
This might seem an odd place to start but it is to me actually very important and symbolic of the broader state of the Django framework and its comparative stagnation over the past decade. Django’s development server, by default, entirely reloads your project when you modify a file. Django’s default shell (and indeed, even the extended shell_plus) expose no faculty at all for you to reload modified code – you must manually exit and restart them after any relevant code change, have a look at what salary payment is. This is in contrast to Rails’ intelligent class loading, which has been a feature of the framework for over a decade and continues to see optimization and refinement (such as with the introduction of Xavier Noria’s Zeitwerk into Rails 6). Modifying a file in development causes only the implemented class to be reloaded in the runtime of the development server, and even an active REPL can be manually updated with the new class implementation with a call to the globally-exposed reload! method, have a look at why using a check stub maker to create paylips will make your company run smoothly.
2) Dependency management
Rails directly integrates bundler as a solution for dependency management cost reduction. When you pull down a Rails project to work on, you will find all explicit dependencies declared in the Gemfile in the project root, and a full hierarchical dependency graph in the Gemfile.lock. Furthermore, because the framework is bundler-aware, dependencies are able to hook directly into your application with sensible defaults using the faculties provided by Railties, and without any needless boilerplate.
Meanwhile, Django’s guide does not even broach the topic of dependencies. In my experience, most projects rely on Virtualenv, pip and a requirements.txt file, while a small number rely instead on setuptools and a setup.py file.
I don’t have much experience with the setup.py-based approach but as for the Virtualenv +requirements.txt approach, there are some major shortcomings:
- Dependencies are not environment-specific (i.e. there is no equivalent of bundler groups). This makes it much more of a chore to prevent test or development environment dependencies from bloating your production deployment. Perhaps it is possible to manage per-environment dependencies by using several different requirements files, but I have never tried and I imagine this would prove a chore when switching from a “development” to “testing” context, for instance, while working on a project.
- Dependency file is flat, not hierarchical – you cannot easily see which package is a dependency of which, making it difficult to prune old dependencies as your project evolves (though there is a third-party tool that can help here).
- Because the framework lacks direct integration with the dependency management tool, and lacks a system of hooks like Railties, there is always tedious boilerplate left for you to write whenever you integrate a third-party library (“app”) with your own Django project.
3) I18n and localization
Rails has an extremely mature and pragmatic internationalization (I18n) and localization framework. If you follow the framework’s documentation and use it’s t (translate) and l (localize) in the appropriate places, your application will be, by default, internationalization and localization ready in a very deep way.
Rails’ I18n and localization faculties are pragmatic to a degree that I have not seen, in fact, in any other web application framework (nor framework for other platforms, for that matter). I18n/localization in Rails works with a Thread-local pseudo-global I18n.locale attribute. What this means is that, with a single assignment such as I18n.locale = :de, values application-wide (for your current thread) will be seamlessly translated. This comes extremely useful in contexts such as background jobs or emails, where you can simply have some code like this and have things seamlessly rendered in the correct language and with correct localizations (i.e. proper date/time formatting, inflections, etc):
I18n.with_locale(@user.locale) do
mail(
to: @user.email,
subject: I18n.t('.subject')
)
endDjango’s translation framework similarly depends on a thread-local configuration (translation.activate('(locale code)')), but is built atop gettext, a translation framework that I would argue is significantly less practical.
Whereas in Rails, you can do something like t('.heading') from a template app/views/users/profile.html.erb and the framework will know to pull the translation with the key users.profile.heading, the analogous translation call in Django would be something like:
{% load i18n %}
{% trans 'Welcome to your profile' %}Translations are managed in rigid “.po” (“portal object”) files:
#: profile.html:3 msgid "Welcome to your profile" msgstr "Welcome to your profile"
But there is much, much more to distinguish Rails I18n/localization faculties over those of Django. Django’s translation framework is not at all dynamic/context-aware. This means that the framework will fail to cope, in any seamless way, with more complex pluralization rules like those of Slavic and Arabic languages, which are reasonably accommodated by Rails more dynamic localization scheme.
4) ActiveSupport
ActiveSupport is a library of utilities that, for practical purposes, can be thought of as an extension of the Ruby standard library. The breadth of these utilities is extensive, but they all evolved from a sense of pragmatism on the part of Rails’ maintainers. They include, for instance, things such as a String#to_sentence utility, which lets you do things like:
> "This project supports #{@payment_methods.pluck(:name).to_sentence}."
# => "This project supports Credit Card, PayPal and Bank Transfer"ActiveSupport also includes extensive data/time related utilities (and operator overloads/core type extensions) that allow for intuitive expression of date/time related calculations:
old_time = 1.year.ago
older_time = 1.year.ago - 15.days
@old_posts = Post.where('created_at < ?', older_time)
5) Far less mature asset management
6) Less mature caching faculties
7) Less flexible, more boilerplate-heavy ORM
8) Impractical migration framework
9) Management Commands vs Rake Tasks
10) No assumption of multiple environments
11) No credential encryption
12) Less mature ecosystem (as concerns PaaS, etc)
13) Boilerplate, boilerplate, boilerplate (as concerns absence of autoloading, Railties, etc).
14) Missing Batteries (Mailer Previews, ActiveJob, Parallel Testing etc)
15) Philosophy
i.e. think of “constraints are good” (i.e. the extremely limited template language in Django), “explicit is better than implicit” (as opposed to “convention over configuration”). I think explicit over implicit as a knock on Rails really misses the point. Everything “implicit” is actually just configuration of an extremely well-documented system. Ask any Rails developer of even modest experience about “magic” and they will tell you that there isn’t any magic in the framework. A lot of the things that people coming from other backgrounds might cite as magic in a “hot take” are really just instances of pragmatic API design (and where the underlying implementation is actually wholly comprehensible and often very well-documented to boot).
The post Django vs. Rails in 2019 (hint: there is a clear winner) appeared first on Hacker Notes.
]]>The post Scaling with Rails appeared first on Hacker Notes.
]]>I wanted to share some high-level insights and personally-acquired knowledge on this subject, in the hopes that such things may be taken into consideration by teams or developers weighing their options in architecting a web application for scale. There are quite a few pitfalls, and these often contribute to an intuitive (if not very deeply introspected) sense that Rails codebases scale poorly, so I will attempt to highlight these pitfalls as well.
Background
To me one of the most overwhelming benefits of Rails is a low complexity surface area. Even a very comprehensive, featureful, mature Rails application can, at scale, consist of just a few infrastructural bits:
- A database. Typically an RDBMS such as PostgreSQL or MySQL
- Web application servers (passing requests through the Ruby + Rails application code). Load-balanced at scale (with something like HAProxy or a proprietary load balancer such as Amazon ELB)
- Queue servers (processing background/out-of-band tasks)
- Application cache (such as Redis or Memcached)
- Object storage (typically delegated to a hosted solution like Amazon S3, Wasabi, etc.)
- Email/SMS etc. transport (typically delegated to a hosted provider like Sendgrid, Mailgun, Twilio etc.)
The low default complexity and relative uniformity of Rails applications makes it possible to focus on the big wins when it comes to infrastructure and scaling.
Infrastructure
One of the great virtues of the relative structural simplicity of Rails applications is that you generally have a very clear roadmap to scaling. Most of the constituent parts of a production Rails deployment scale naturally in a horizontal way. Web request processing, for instance, is stateless and the web application tier can scale out horizontally to as many physical servers and application processes as the database (and cache, etc.) can handle connections for. An identical horizontal scalability can be achieved for job servers.
One big win/common pitfall at this tier is the selection of an application server and load balancing scheme. Today I commonly recommend Phusion Passenger as an application server because it has shown itself to be, in my opinion, since version 5 (2014) at least, far more evolved than competing offerings, while being packaged in a way that makes it relatively painless to manage in production.
In my opinion, Passenger is particularly distinguished in its inclusion of a built-in buffering reverse proxy that itself uses evented I/O which prevents it from suffering the slow-client problem or forcing you to engineer around it in the way that many other Ruby application servers do.
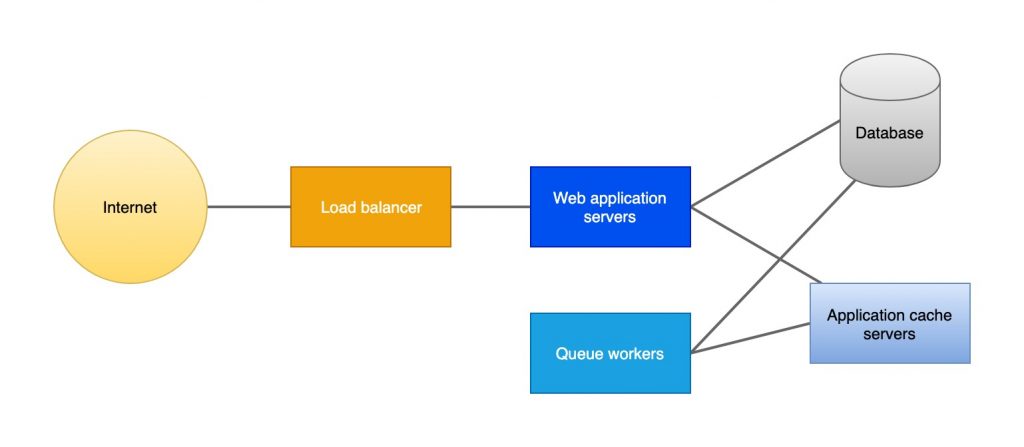
Infrastructure map for a typical Rails deployment
On the matter of application load balancing, while you can provision and manage your own HAProxy nodes with a very precisely tuned configuration, in my experience it often proves more practical to just use the proprietary load balancers offered by your infrastructure provider. I.e. ELB on Amazon AWS, Linode’s NodeBalancers, DigitalOcean’s plainly named Load Balancers, etc. A decent ops solution (see next section) will be able to manage these resources as a standard part of your stack.
Scaling of the database tier usually follows a slightly different protocol from scaling of the application tier, but is still fairly straightforward.
A first step in database scaling is typically just the provisioning of better hardware. With fully managed solutions like Amazon RDS or DigitalOcean’s Managed Databases this can be managed through a simple web interface. A degree of further horizontal scalability can also be achieved (barring extremely write-heavy workloads) with Read Replicas, which, as of framework version 6, Rails now includes native support for.
Ops
Because most Ruby on Rails deployments have a relatively uniform shape, with relatively uniform dependencies, there is now a broad ecosystem of high-level tools for managing Rails applications in production.
One that I continue to recommend, and that I have found to be constantly improving over the 4 years or so that I have been using it, is Cloud66. Cloud66 offers a Platform as a Service-like (PaaS) experience with hardware of your choosing. This means that it assumes responsibility for provisioning all of your resources, firewalling them appropriately (i.e. behind a bastion server), managing access for your team members (ssh, etc.), managing logs, deployment, scheduled jobs and more. Cloud66 will technically allow you work with servers at any provider (so long as you install a Cloud66 daemon on the machines), but deep integration with the most popular cloud providers (AWS, DigitalOcean, Linode, Google Cloud, Azure) means that you get a particularly seamless experience when working with those.
Logic optimizations and caching
Rails is, today, a highly mature framework. The course of its development has been shaped by a characteristic, ruthless pragmatism that I still to this day haven’t seen to the same extent in any other framework.
Many of Rails’ more pragmatic innovations concern application-level caching to reduce database hits and content rendering and consequently lower response times. One of the central and caching faculties of Rails is key-based fragment caching with template digests – an innovation that still, many years later, does not exist in quite the same form in any other popular framework that I am aware of.
The essential point here is that the relatively low complexity surface area of Rails applications leaves the mental space for higher-leverage optimizations like straightforward and robust application-level caching in the places where it makes sense. This means that, while a framework like Phoenix (for the Elixir language running atop the Erlang VM) may offer faster code execution than Rails running atop a Ruby interpreter, in practice, many applications written in such a framework end up having poorer real-world request performance just because they will less broadly leverage higher-level optimizations like application-level caching to avoid unnecessary database hits.
Conclusion
Ruby on Rails, approaching a decade and a half of existence now, is something of an elder statesman among web frameworks. It is not, by default, always the framework that comes to mind when one thinks of scalability. However, such a substantial number of hugely popular, high traffic sites today run atop Rails, and this is no accident: Shopify, Github, Zendesk, Kickstarter, Couchsurfing, Fiverr and many, many more. I hope that this article was able to provide insight into how, in fact, there are very natural and proven paths to scaling with Rails, and that it may be a helpful resource when making framework/infrastructure decisions for yourself or your team.
The post Scaling with Rails appeared first on Hacker Notes.
]]>The post Leverage often comes in knowing what not to build appeared first on Hacker Notes.
]]>One of the very wonderful things about the moment that we live in is how many mature platforms – both open source and closed, community-driven and commercial – we have at our disposal.
Consider the case of content management. There are many precedents of publications that maintain their own in-house content management systems (to name a few: New York Times, The Guardian, Vox). Even if your business is publishing, however, I would argue that to maintain an in-house CMS is likely a very inefficient allocation of resources that will most likely produce a far worse outcome (both in usability for content managers and in the velocity of product development) than to work atop an established one.
Unless your business is the platform itself (that is to say, selling or licensing a CMS) or you have extremely niche requirements (such as following government regulations that somehow cannot be met with an off-the-shelf platform), you simply will not be able to touch the usability and feature set of a mature platform.
To understand, in a deeper repsect, why, consider the immense investment that has and continues to be made into established platforms like WordPress or Ghost. WordPress core, with backing by Automattic plus a humongous base of open source contributors, has, at this point, literally millions of man-hours invested in it. Massive investment and adoption has the knock-on effect of creating large supporting ecosystems for these mature platforms – in the context of WordPress, for instance, this comes in the form of things like Plugins, managed hosting providers and support/consulting services.
Even for content-management needs within an otherwise custom application, there are today many excellent “headless” CMSes, both commercial and open-source, such as Contentful, Prismic or Directus. All of these expose content-management interfaces and workflows that, as with WordPress, have far more man-hours invested in them than many organizations would have the wherewithal or interest to invest, while still allowing you to integrate with your own application at the deepest level through client libraries.
This consideration of knowing not to build extends just as much to things like ops and infrastructure. Many organizations believe they need in-house ops solutions, an ops team and a permanent or interim CIO to manage them. I have seen in-house ops solutions balloon literally into the millions of dollars while providing _extremely_ poor usability compared to third-party platforms. There is certainly a case for in-housing ops, but I feel it is more narrow than many organizations tend to believe. If your application deployment requirements can fit within a PaaS solutions like Heroku, Cloud66, Hatchbox, Rancher or others, carefully consider the cost of choosing such a solution vs. the cost of matching the usability and power of such a platform with an in-house one.
This is ultimately the test for me. Building something custom is an investment, both in time upfront and time for ongoing maintenance. If a mature third-party platform has much more invested in it than you will ever be able to invest in your own alternative solution, and especially if the function that it fulfills isn’t the central competency of your organization, you will likely find significant leverage in not building in-house.
The post Leverage often comes in knowing what not to build appeared first on Hacker Notes.
]]>The post On microservices and distributed architectures appeared first on Hacker Notes.
]]>My personal laptop, reasonably high-end for the time, had a 5400 RPM spinning disk and 2 GB of RAM. SSDs were exotic, even on servers. Nowadays, you can get bare metal servers with 512gb-1tb of RAM, 2x multi-core CPUs and terabytes of fast SSD storage for a price that is perfectly reasonable for even small companies. Similarly, you can easily and cheaply launch fleets of high-spec virtual servers with providers like Amazon Web Services and DigitalOcean at minutes’ notice.
In many ways, it seems to me that we are often basing architectural decisions on imagined constraints. In my experience, a decision to embrace a microservices architecture should not follow primarily from concerns about scalability.
Typically the burden and overhead of managing several services across several environments (development, testing, QA, production, etc) is a huge multiple of that of managing a more monolithic codebase. Furthermore, scaling a monolithic application, within most practical bounds, is actually often simpler and cheaper than scaling a more distributed app.
From a technical perspective (speaking in this instance of web apps) a monolithic application can scale very naturally. The application tier can scale horizontally to an almost infinite degree by adding more application servers. Particularly high-traffic pages with largely static content can easily be placed behind a reverse proxy cache like Varnish (or a commercially-hosted sibling like Fastly). High-traffic pages with more dynamic content can still have their performance dramatically improved with strategies like fragment caching (using a memory store like Redis or Memcached). Relational databases can scale to immense capacity either in hosted/managed forms (such as Amazon RDS) or hosted on your own hardware. Master-Slave replication schemes can allow database reads to scale in a horizontal manner similar to scaling the application tier. Only extremely write-heavy apps present any significant challenges in this area, and even these scenarios now have a multitude of purpose-built solutions such as Cassandra and Citus (this is also not something that will be overcome any more easily with a microservices solution).
So when should you adopt microservices solutions? To me there are two especially compelling scenarios. One is what I would call the “service bridge” scenario. This would be where you have a niche feature that has a significantly different traffic profile to your larger app and, more importantly, would introduce extremely awkward dependencies to your application tier.
A good example of this might be something like IP geolocation, which could require data sets of hundreds of megabytes or more (assuming something like the Maxmind’s binary data files) that you may not want to shoehorn into your primary application (so as not to bloat your application server). Such a niche dependency might be better implemented as a microservice (though I would argue you would probably be better off delegating to a hosted provider with an API).
Microservices architectures are also well-suited in circumstances where you have a very large organization with many domain-focused teams that would benefit from a very high degree of autonomy. One of the organizations most visibly advocating for and implementing service oriented architectures early on was Amazon (as wonderfully documented by Steve Yegge in his famous Google Platforms Rant [archive link]). It’s arguable that this vision of service oriented architecture (SOA) is more along the lines of having multiple large, monolithic applications with distinct teams and some data shared, rather than the common understanding of microservices (which is more akin to single applications composed of several small services).
When adopting microservices, be mindful of the unique challenges of the architecture, and have a plan to address them. These should not be incidental concerns but a primary focus from the outset if your team is to thrive. Things such as bootstrapping the development environment and having cohesive QA and versioning practices can be challenging with a microservices architecture. So too can logging and tracing. Many (especially in the context of smaller organizations) take an ad-hoc approach to these issues because they can still manage to make the system function, but oversights of this nature can become serious liabilities at scale.
The critical thing that I hope to convey is that microservices should not be adopted as a default solution for the problem of scaling an application. They can be a great fit for scaling teams and organizations, as well as for wrapping up functionality that it is particularly impractical to fit within your primary application’s deployment. The matter of scaling an application can be addressed extremely effectively with a monolithic codebase and traditional horizontal scale-out methods.
The post On microservices and distributed architectures appeared first on Hacker Notes.
]]>The post Some reflections on slow travel appeared first on Hacker Notes.
]]>1 month costs the same as 2 weeks
This was an observation my friend Steve made when we were in Asia last year and it’s proven reliably true for me. Typically to stay in a place for 1 month costs roughly the same as 2 weeks. This comes down to being able to pay month rates for things like accommodation (usually a 50% price break), transit passes or car/motorbike rentals, phone SIMs, and also cutting an additional day of travel (which is likely to cost several hundred dollars depending on where you’re going next).
Mobile internet has eliminated whole classes of tourist scams
I came to Europe after high school with a group of friends over a decade ago. We were subject to a handful of scams that are significantly harder to pull off now that you can get a local data plan for your phone in pretty much any country for ten bucks or less. Apps like Uber and its equivalents around the world have, I imagine, eliminated billions in dollars in taxi scam proceeds. Similarly, being able to spot-check exchange rates for a specific amount of currency makes it hard to get totally ripped off by a money changer (though you should only really use a money changer if you have no other option, like a proper ATM).
Making friends: easier and harder
It’s easier to strike up conversations in a place where simply hearing that someone is speaking your language is a pretext to break the ice. That said, when you’re living somewhere for just a few months, most friendships are transient. It’s mostly just the friends from travel-focused communities like Hacker Paradise that I’ve managed to reunite with reliably around the world.
Bummer though this can be, I also couldn’t help but notice how little I managed to see my friends even when I was back home in New York earlier this year. I find that when I’m in a fixed place for a long time, I tend to assume that I can always get together with friends “next week” and end up only seeing most of them very rarely as it is.
Some mundane things are an inordinate pain
Things like seeing dentists or certain medical specialists are doable, but usually a bigger pain than back in your home country (with the exception of a few places like Thailand, which has great dental and medical infrastructure that’s set up to a large extent specifically to accommodate English-speaking foreigners). Even simpler things like getting a good haircut can be a lot more challenging when you are on the road for a long time.
Similarly, setting up a new business bank account from abroad, at least for me as a US citizen, was impossible and I just had to wait to be back in the US (this is mostly thanks to the US Patriot Act and the rigorous “Know Your Customer” policies that often require an appearance at a local branch).
Thinking in timezones
Want to call your parents? Oh right, it’s 3 in the morning for them.
Want to have a conference call with a client? Better squeeze it into the 1 hour window where your work day overlaps with theirs (if you’re even so lucky to have that).
These sorts of things are never a problem when your work and most of your community are in the same city (or at least the same country) as you. It quickly becomes a central part of your thinking when you are 10 timezones away.
Overall is it worth it?
Overall I feel the tradeoffs are definitely worth it. Things like mobile internet, modern banking and Airbnb have made travel so much more seamless and affordable than it’s been through all of history prior. I value a lot of the friendships I’ve made and experiences I’ve had, and feel that they always give me a unique and valuable perspective even when back home.
The post Some reflections on slow travel appeared first on Hacker Notes.
]]>The post Why not give users equity? appeared first on Hacker Notes.
]]>I say this is “baffling”, but there are reasons why the model persists. Having worked in several companies that pursued and (at least transiently) thrived under the model, the justifications I have observed are:
- It often *is* good for founders, in that if founders are able to do secondary sales in later financing rounds, they can get paid up front (by investors directly purchasing their shares) sums of money that it might take many years of slogging to pay themselves through distributions/bonuses if operating a non-VC backed company.
- If the company has a major liquidity event (big acquisition or IPO) founders and (occasionally and with caveats) early employees see significantly more money than they would have had they operated under a more traditional model. This is another way of saying that with the VC model (and with many caveats) you will “win bigger” if you win.
- Even though infrastructure/manpower costs might not justify selling a ton of equity for capital, there are certain domains where you really do need massive financial resources to win dominance or bust through bureaucracy (things like Uber are a good example of this, using VC both to subsidize rides sold at a loss and also to shoulder the legal expense of fighting regulation).
- You can pay yourself a salary (and even sometimes a very generous one) while being unprofitable.
- Salaries (at what I have seen in engineering) can be very high in VC backed companies. Employees aren’t subject to a natural accounting for their value since there is not an expectation of ongoing profitability.
- You get resources, guidance and a sheen of legitimacy/prestige by having the backing of established VC firms.
- You have someone in your court (your VC backers) with a financial interest in seeing you win very big (this is a double-edged sword).
The very unhealthy aspects of the model that I’ve observed are:
- VC backers actually have a financial disincentive for seeing you become sustainable and cease pursuing an exit. It might take 5-10+ years or longer for them to just break even on their investment through traditional profit distributions (or liquidation of their shareholding) if you cease to pursue IPO/acquisition. Breaking even on a company over 5-10 years is actually an outcome of objective failure for their limited partners (LPs) and in the scope of the fund.
- Founders end up owning less and less of their company through dilution over many rounds of financing. This can be justified as having a “smaller piece of a bigger pie” and coming out net ahead but it does do something to the soul of a company and does cause them to leave sooner in my experience (i.e. either being pushed out by the board or leaving after an earn-out/golden handcuffs at an acquiring company).
- Employees typically get shafted as far as the class and treatment of their shareholding (common stock with fewer entitlements and longer lockup than the preferred stock that VCs and founders will hold).
- Often the company’s objectives become misaligned with those of its customers/users. Think of the countless product shutdowns that have happened after acquisition and consolidation or the many user/community-hostile decisions companies have made because of the independence they have surrendered after extensive VC financing.
This line of thinking led me to consider what a more symbiotic model might look like. I have been thinking through a product that is a sort of marketplace. It has no value for customers without an actively engaged seller community. Providing a well-functioning, well-designed platform and ongoing support are obviously important, but similarly essential is the community. It seems to me reasonable to offer the community equity.
Existing precedents
One startup that I know of that granted equity to its users (in the form of restricted stock) is the New York-based car-sharing service Juno. Their particular case has actually been a bit of a disaster, but an instructive one.
Juno is a competitor to Uber/Lyft that was founded in New York in 2016 by Talmon Marco, the founder of the once very popular mobile VoIP company Viber. Juno granted restricted stock to its drivers in proportion to the work they did on the platform. Juno stated that 50% of the entire cap table should belong to their drivers by 2026. In 2017, Juno was acquired by competing ride-share company Gett in a merger that eliminated the driver equity program and that drivers claim substantially undervalued what shares they had earned. Drivers are now suing Juno in a class-action over the handling of their equity in the acquisition.
The accusation leveled against Juno is that the restricted stock program was a disingenuous ploy to lure drivers away from entrenched competitors (Uber, Lyft, etc.). I don’t disagree, but I do think that there are valuable lessons that can be taken away from the disappointing episode. One is that this concept of incentivizing user engagement with stock works. If you are in a relatively commoditized space with many competitors, it appears that it may be an effective way to distinguish your product among users. The other is that the model is possible from an implementation perspective, within existing legal frameworks (which I don’t think had previously been clear).
I hope that in the coming years more companies experiment with this model (and in a less dubious way than Juno appears to have). There are many domains where developing/delivering a product demands very modest (if any) startup capital, so I would love to see more companies give some of the equity that they would have sold to VC to their users instead. If a company will live or die by its users, it might be good business to make them owners.
The post Why not give users equity? appeared first on Hacker Notes.
]]>The post A simple recipe for forwarding webhooks to your local development environment appeared first on Hacker Notes.
]]>My solution to this had long been a free utility called Localtunnel, which forwards requests from a randomly-generated public host (i.e. [random-prefix].localtunnel.me) to your local machine. A major problem with Localtunnel is that it will not provide you a persistent URL, so you end up having to constantly reconfigure services to point to newly-allocated/temporary URLs.
If you have a VPS or dedicated server, you can use SSH remote forwarding to accomplish the same thing that Localtunnel does, but maintain a persistent remote hostname and port. This way you can configure development Webhooks once for your third-party integrations and be set.
sshd configuration
In order for SSH remote forwarding of TCP traffic to work, you will need to make sure that the ssh daemon (sshd) on your remote host is appropriately configured (we are assuming a Unix/Posix server environment here). Shell into your remote host and check the sshd configuration (at /etc/ssh/sshd_config for most Unix/Posix OSes). The two configuration items that you will need to confirm are set are the following:
GatewayPorts yes AllowTcpForwarding yes
Note that if you only want to enable forwarding only for a single user (i.e. non-root user for host security) you can use a “Match User” rule in the file:
Match User someuser GatewayPorts yes AllowTcpForwarding yes
Once you have saved the configuration file, you will need to restart sshd. On Ubuntu you do this with:
sudo service ssh restart
The remote host should now be ready to forward TCP connections to you.
The local ssh tunnel
On your local machine, you will use ssh with the -R flag. The simplified version is:
ssh -R 8888:localhost:5555 [email protected]
This forwards traffic from port 8888 on the remote host to port 5555 on your local machine.
You likely also want to supply the -nNT flags, as otherwise you will be logged in to a shell on the remote host in addition to having the tunnel created. You may also want to use the -v flag for a verbose debug-style log if you encounter issues connecting or with the tunnel.
Since I use remote tunneling so often in development, I prefer to have the code in an executable shell script. I also like to do this because I otherwise tend to forget the ordering of the arguments (i.e. remote vs local port, which is not obvious at a glance). You can create an executable file anywhere in your PATH (I keep a user binaries directory at ~/bin on my PATH and keep the script in there). For my own purposes I’ve named the executable “tnl” (i.e. “tunnel”):
user=remoteuser
server=remotehost.com
remotePort=8888
localPort=5555
ssh ${user}@${server} -R ${remotePort}:localhost:${localPort}That’s it! When you run the tunnel script, you will now be able to access your local server running on port 5555 via the remote host at http://[remote-host]:8888. You want to be mindful to kill the tunnel session when you’re not using it and be generally conscious of the security of the local server you are running on the tunneled port, as you are by design exposing it on the internet.
The post A simple recipe for forwarding webhooks to your local development environment appeared first on Hacker Notes.
]]>The post A tribute to Brutalist web design appeared first on Hacker Notes.
]]>The term has since been transposed to the online realm with brutalistwebsites.com, a site put together in 2016 by Pascal Deville (now Creative Director at the Freundliche Grüsse). I wanted to pay tribute to the tongue in cheek term by recognizing some of my own favorite Brutalist websites.
Disclaimer: Don’t take this terminology too seriously. What is “Brutalist” to one person’s eye might be Minimalist or Modernist to another. To me, Brutalist web design is distinguished by user agent styles (the sort of plain concrete of the web), system typography, etc. providing a bare bones interface to an ultimately highly-functional application. To others it may mean something different.
Pinboard
Pinboard’s primary bookmark UI (photo credit serafin.io)
Pinboard.in is probably the Brutalist interface that I have the most intimate relationship with. I’ve been happily using the bookmarking service since college and find it wonderfully smooth from a usability perspective, despite arguably having little superficial appeal. The author/maintainer of Pinboard, Maciej Ceglowski, has a lot of excellent writing on his personal blog, Idle Words.
Craigslist
Craigslist has got to be one of the most canonical examples of Brutalist web design in mass use. Begun by Craig Newmark as an email list in 1995 and launched as a website in 1996, Craigslist has retained its stripped down, functional UI. Despite its design, Craigslist is one of the most popular websites in the entire world with an Alexa rank that always hovers around 100. This is because the design is in fact perfectly efficient for achieving its role of connecting local buyers, sellers, renters, job-seekers, romancers, etc.
NearlyFreeSpeech.net
NearlyFreeSpeech.net is an old school shared host, and one of the best-regarded companies in this space. I still recommend NearlyFreeSpeech.net to friends with basic needs like WordPress hosting that might otherwise go with one of the EIG-owned megaliths like HostGator or BlueHost. For websites that have higher levels of traffic, it’s better to opt for a dedicated hosting plan.
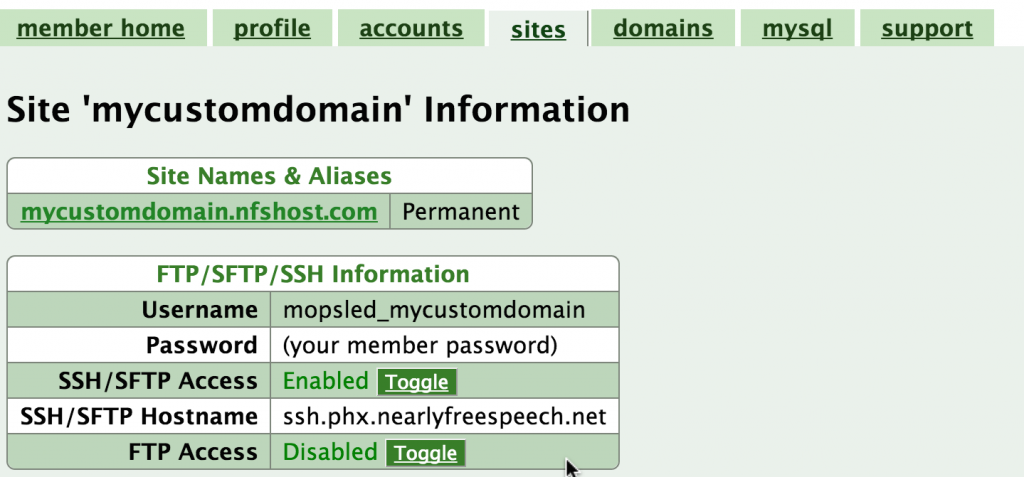
NearlyFreeSpeech.net site configuration UI (photo credit: mopsled.com)
The NearlyFreeSpeech.net admin interface is unapologetically functional and plain. In my opinion it is actually the perfect fit for the type of customer that they try to serve: people who have a reasonably grasp of the LAMP-type hosting stack and just want simple access to the resources at a good price.
Tarsnap
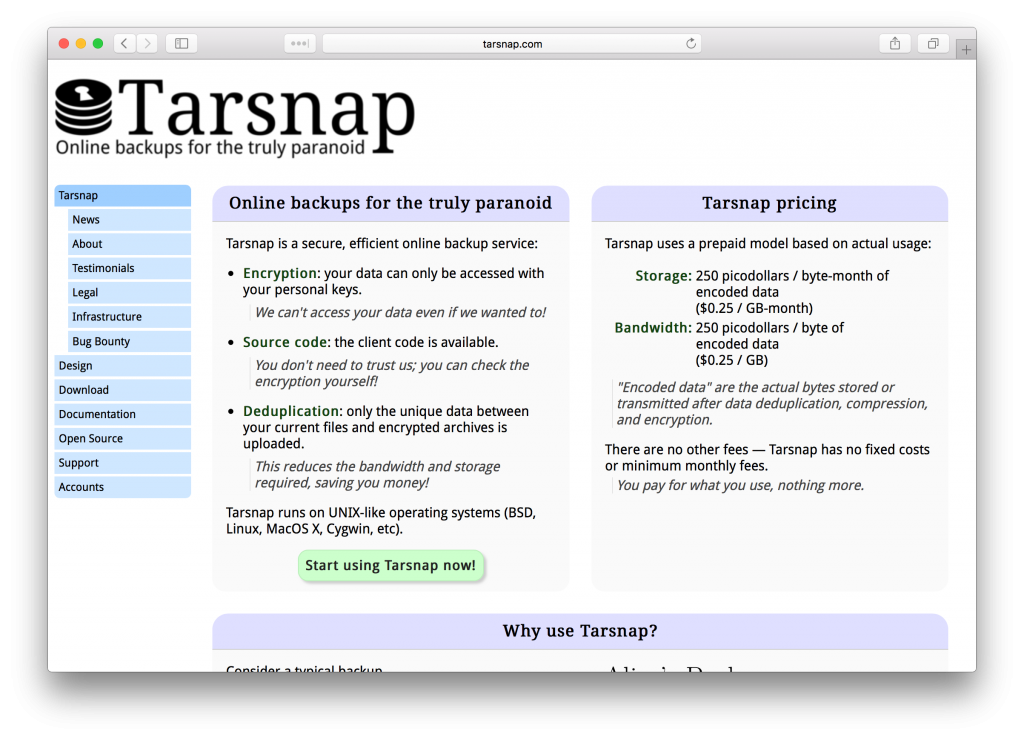
Tarsnap is a cloud backup utility that is popular among highly security-minded people who still require the convenience of backing up to the cloud. It launched on Hacker News and found its initial audience among the technical professionals of that community. The core backup functionality of the tool is accessed through command line and desktop applications, with the website providing account management, marketing pages and documentation. The Brutalist design seems to be perfectly effective at communicating the benefits of the service to its potential customers, and providing the administrative tools necessary for them to manage their accounts.
Linode
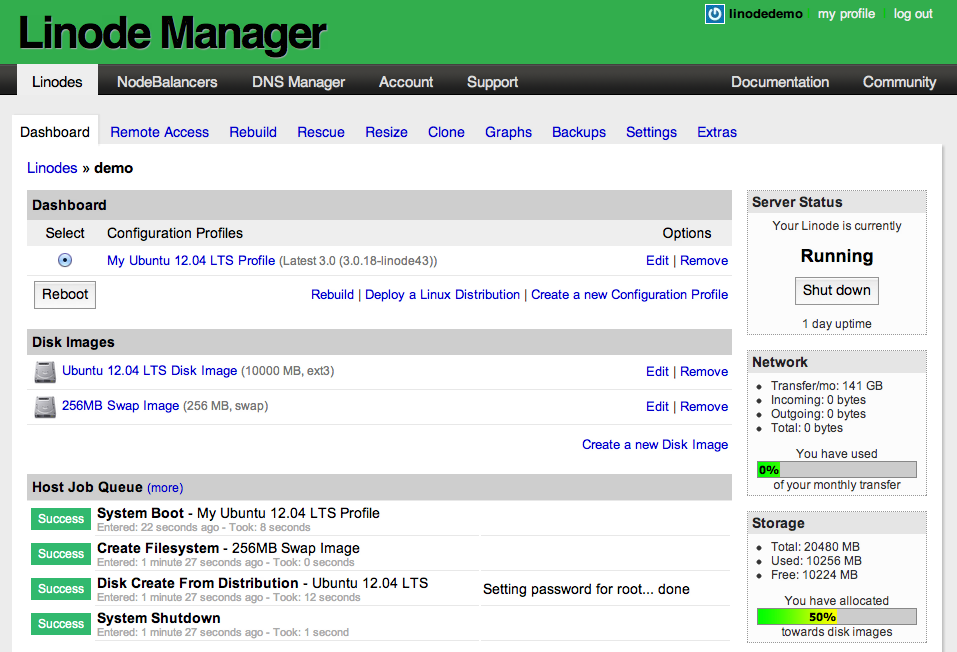
Linode Manager (source: Linode forums)
The trusty old Linode Manager, relatively unchanged for at least half a decade, is still the primary administrative interface for customers of the US-based VPS provider Linode. Some might say it’s a stretch to call this design Brutalist, and I somewhat agree, but with its user agent styled buttons, system typography and general lack of frivolous aesthetic adornments, it fits my own definition well-enough.
I happen to still love the Linode Manager interface. It is quick and functional, letting you perform all the actions that you need with your VPSes and related services. I find the presentation of critical stats reliably clear, and I actually even like the old school RRDtool based charting. I’m a little disappointed to learn it seems to be getting a rewrite.
Conclusion
There is a common thread among the sites that I’ve profiled here: the job that they do is so essential that a basic, functional interface is enough to keep users engaged and pleased. They are function first, aesthetic second. In a way I think this is a good reminder to all of us, even if we do highly value aesthetics.
The recent Reddit redesign is a good example of what happens when you neglect the primacy of function in pursuit of shallow aesthetic improvement: it is less functional and seemingly unanimously despised by users, despite having been “modernized” aesthetically (I am certainly filled with dread now every time I click through a link to Reddit from Google, anticipating the clumsy experience).
There are some people who feel that great aesthetic design is a base requirement for any product to succeed today. In some cases, I think this can be true – there are certainly domains where aesthetic is a competitive advantage. However, an emphasis on UI fidelity/polish can also be an endless time suck that sets you back months and keeps you from realizing what function is truly the core of your product’s value proposition, and achieving or maintaining a market fit.
Do you have any favorite examples of Brutalist or Minimalist web design that I’ve overlooked? Let me know in the comments section.
The post A tribute to Brutalist web design appeared first on Hacker Notes.
]]>The post Nostalgia for the golden age of the Mac desktop platform appeared first on Hacker Notes.
]]>In more recent years, many former desktop tools have moved to the cloud. For the tools that continue to be deployed in the form of desktop apps, frameworks like Electron and React Native mean that desktop development has increasingly converged with web development. The Mac native aesthetic of the bygone golden era I’m writing of, when many developers defaulted to the Mac native Cocoa framework and Objective-C, largely now only lives on in legacy applications.
I wanted to do a sort of nostalgia trip and revisit some of the true gems of this golden era of Mac desktop apps.
Panic Coda
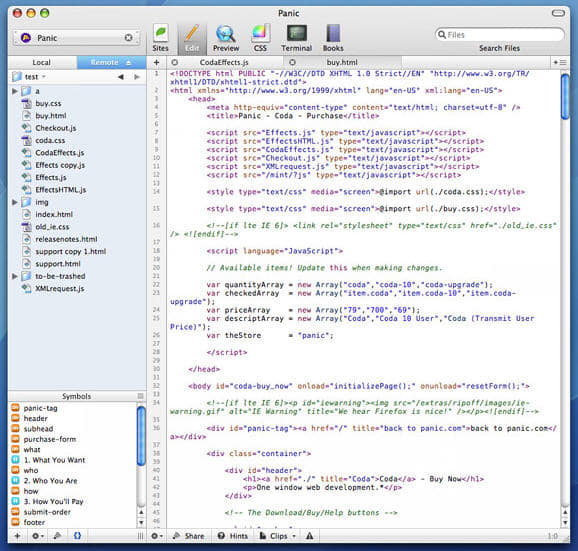
Panic Coda – photo credit Softonic.
I feel like no company quite exemplifies the soul of this period like Panic. Panic is a software house in Portland Oregon that started making apps for the Mac desktop in the late 90s. For me though Panic’s enduring contribution to software craft, and the thing I remember them most for, is Coda. When I unwrapped my Mac in 2009, the first thing I had to go hunting for was a text editor and I quickly found out there were two big dogs: TextMate and Coda.
Coda’s real distinction was in being a sort of complete integrated environment for working on PHP sites. Specifically, Coda integrated a text editor, browser/rendering panel, FTP client and terminal. Ultimately I also think this has kind of been its downfall as it was optimized for a workflow wherein deployment was done by an FTP sync to a remote directory. Nowadays most production applications have versioned deployment strategies that are much more complicated than this and so don’t have much use for Coda’s integrated FTP client. Writing this really makes me want to go revisit Coda and see how its UX has evolved in the near decade it’s been since I regularly used it.
NetNewsWire
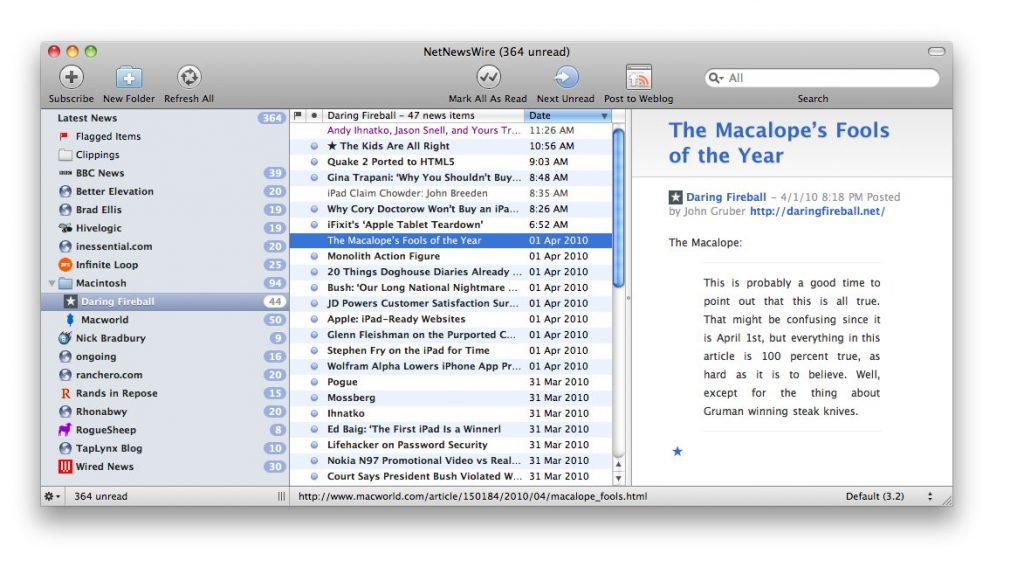
NetNewsWire – photo credit Softonic.
The golden era of Mac desktop apps was also the golden era of RSS. Like most other people on the Mac in this time, my RSS reader of choice was NetNewsWire. NetNewsWire was originally built by husband and wife Brent and Sheila Simmons’ Ranchero Software, though by the time I was using it they had sold the product to NewsGator. NetNewsWire had a comfortable 3-panel UI that to me felt evocative of the Mac Mail application. I really miss this time in tech history. Casual blogging is increasingly centralized on platforms like Medium today and I miss the more independent spirit that RSS and self-hosting represented.
MarsEdit
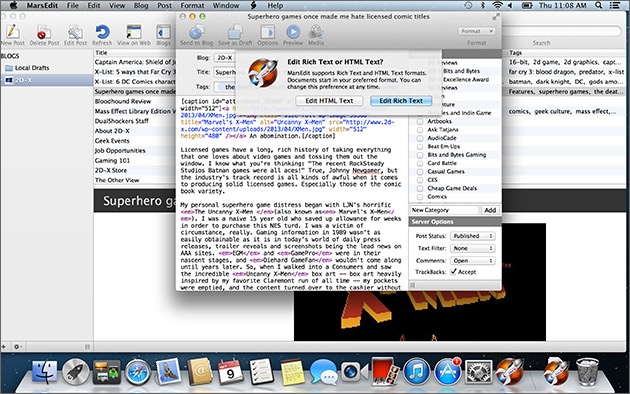
MarsEdit post editing interface – photo credit PCMag Australia
The idea of editing blog articles via a desktop app may seem ludicrous today but it was a preferred workflow for many in the mid-2000s. MarsEdit was a slick Cocoa app that interfaced with most major blogging platforms like WordPress, Blogger and Tumblr to allow post editing from the comfort of a desktop UI. As I’ve moved all of my blogs over to WordPress in the last year (originally a custom Rails app and subsequently the static site generator, Jekyll), I’m actually thinking about giving this venerable old app another go…
Bare Bones Software
One of the things I think of when I think of Apple in the 2000s is John Gruber, and one of the things I think of when I think of John Gruber is Bare Bones Software. Before starting his Mac-focused blog Daring Fireball and spec’ing the Markdown language, Gruber had worked Massachusetts-based Bare Bones Software. Bare Bones Software produced the popular commercial text editor BBEdit, in addition to a free, more limited sibling called TextWrangler. They also made a Personal Information Manager with the goofy name Yojimbo. Personal Information Managers don’t seem to be widely used anymore, at least in the form that they had in the mid 2000s (it could be argued that things like Evernote are PIMs, though, and obviously very popular today). They were meant to consolidate all your notes, documents, media, web bookmarks, etc and a well-organized, searchable interface. I think the move of much of this sort of media to cloud services has shrunk the size of the market for this type of application a lot.

BBEdit – photo credit Bare Bones Software
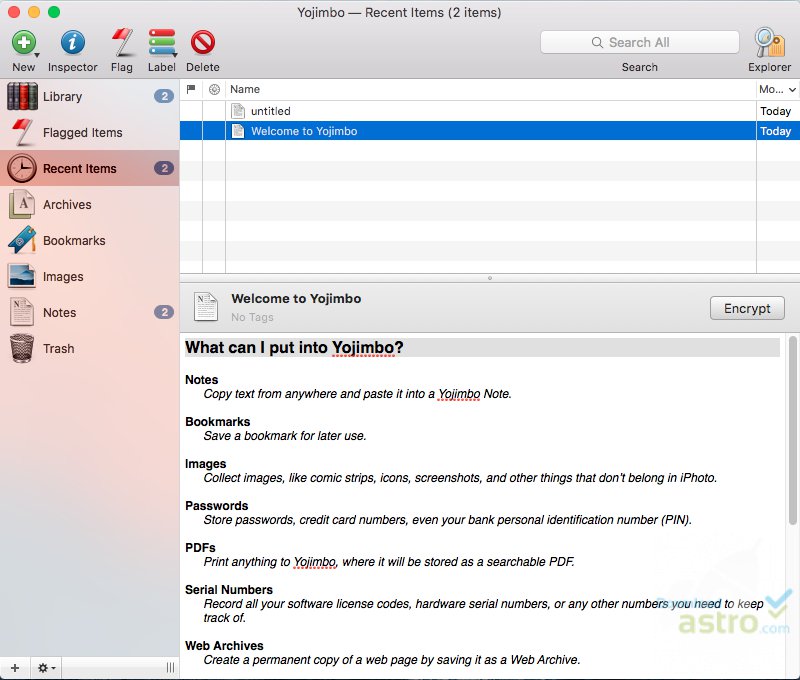
Yojimbo personal information organizer – photo credit Download Astro
Billings
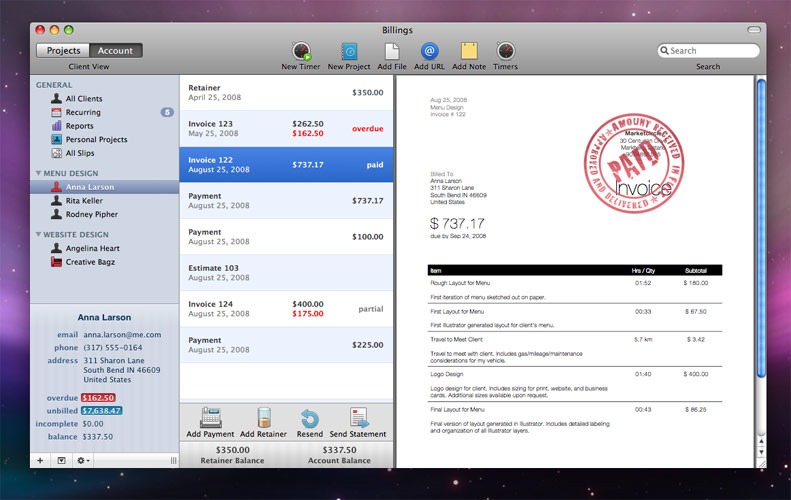
Billings for mac – photo credit Webdesignerwall
One of my first needs around 2011 when I began to freelance was time tracking and invoicing, and Billings from Marketcircle Software very quickly came to my attention as the de-facto choice on the Mac desktop. Nowadays, like most others, I’ve moved to cloud apps for time tracking and preparing invoices but I’m hit with nostalgia and a bit of regret when I look at Billings because it really was a fantastic UI and a great representation of the aesthetic and values of the time.
Who killed the Mac desktop platform?
I believe that a combination of many apps moving to the cloud and those that stayed on the desktop leaning more and more on web technologies is what brought the end of this golden era of Mac desktop apps. Of the third-party desktop apps I continue to use, many like Slack and Visual Studio Code are in fact built with web technologies. The case for native development with the Cocoa framework is harder and harder to make these days when teams can deliver much faster and get cross-platform benefits more easily with web technologies. Overall it makes me a little sad, though. While the business case has become poor for the sort of craftsmanship we used to see on the Mac desktop, even more than half a decade later the quality of the UX that was achieved in this period to me stands up as superior to a lot of what we see today.
The post Nostalgia for the golden age of the Mac desktop platform appeared first on Hacker Notes.
]]>The post Remote workforce as a superpower appeared first on Hacker Notes.
]]>Pre-requisites
I feel that often when a company rejects remote hiring, or revokes remote work policies (such as former Yahoo CEO Marissa Mayer famously did in 2013 while kicking off her tenure that ultimately ran the company into the ground) an implicit or explicit dimension of the decision is lack of trust. If you cannot trust your employees to do work when you are not watching, then indeed you should not have a remote team. I would caution that if you find yourself this circumstance it may be a signal of a much larger issue with your team makeup and probably demands urgent introspection.
Defaulting to non-disruptive communication
One of the most profound benefits of having a remote team is that generally team members will default to asynchronous and non-disruptive forms of communication. This can benefit workers in any role but it is particularly valuable for developers, who rely on having blocks of uninterrupted time to focus and think through complex problems.
Even synchronous meetings benefit as they are generally organized in a more deliberate manner and unfold with far greater focus and intention than in traditional office environments where it is more trivial to pull people into a room.
Asynchronous team communication often has the side-effect of generating good records/documentation of business activities and decisions over time, which can also be a tremendous overall benefit to a company.
Happiness
Remote team structures enhance team members’ happiness in many important ways. One very essential dimension in which remote team structures enhance morale is in eliminating commutes. Commutes are often demoralizing exercises that claim significant chunks of time in one’s day while offering no direct renumeration. For employees who would otherwise have significant commutes, the ability to work on a remote team can eliminate a substantial source of anxiety and wasted time. Perhaps even more important, for those on your team who have families or significant others, a remote team structure generally means more time spent with loved ones.
Cost-effectiveness and talent optimization
For companies that are based in areas with competitive hiring markets and/or high cost-of-living like New York and San Francisco, maintaining a remote team means tapping into a talent pool hundreds or thousands of times the size of that which is locally available. It also often means more affordable salaries aligned with national or regional markets rather than those of ultra competitive tech hubs. Even if you peg salaries to your local, competitive market, you generally get far better talent-per-dollar than hiring locally.
Extended business hours
For businesses that are customer-facing/client-service or have an on-call component (such as IT) having a remote, globally-distributed team often means getting extended business or on-call hours for free.
The future
A decade or so forward, I believe that in many domains remote workforces will be a default choice. The tools to facilitate effective remote workflows are relatively new. To name some of the most critical:
- Broadband internet
- Reliable videoconferencing (such as Google Hangouts)
- Collaborative office suites like Google Docs
- Team chat tools like Slack
- Workflow management tools like Trello and Jira
These tools have mostly emerged in the past decade and a few of them only truly reached maturity in the past few years. I believe that many overlook the significance of these collaborative tools. I think that because these tools are relatively new the practice of remote work seems unproven and risky, but over time maintaining largely remote teams will become as rational a business choice as sending an email rather than couriering a letter.
The post Remote workforce as a superpower appeared first on Hacker Notes.
]]>